
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 데이크루
- 지도학습
- 디지털직무
- 일반상식
- 과대완전
- 데이콘
- Python
- IT용어
- 디지털
- 머신러닝
- 데이터분석
- 금융권
- dacrew
- 금융상식
- 디지털용어
- 비지도학습
- IT
- 과소완전
- Jupyter Notebook
- 주피터노트북
- 금융
- 은행채용
- 직무역량평가
- jupyternotebook
- 파이썬
- 은행
- 알고리즘
- 파이썬문법
- 군집분석
- 사전학습
- Today
- Total
Ming's blog
kaggle) Titanic data 분석하기 1. 데이터 전처리 본문
파이썬을 이용하여 kaggle에서 가장 기본으로 알려진 타이타닉 데이터를 분석하고자 합니다.
먼저, 데이터 분석에 앞서 필요한 패키지들을 불러옵니다.
numpy와 pandas 그리고 시각화를 위함 matplotlib과 seaborn을 불러오겠습니다.
또한, 통계분석을 위해 scipy와 NA값을 쉽게 보여주는 missingno를 불러오겠습니다.
마지막으로, warnings를 불러와 필요없는 경고 메시지를 표현하지 않도록 하였습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
%matplotlib inline
#na값 쉽게 보는 함수
import missingno as msno
# Warnings 메세지제거
import warnings
warnings.filterwarnings('ignore')
1. 데이터 불러오기
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')train데이터와 test데이터를 불러옵니다.
print(df_train.shape,df_test.shape)
#(891,12) (418,11)
df_train.head()# df_train : 891개의 obs 12개의 설명변수, 1개의 종속변수
# df_test : 418개의 obs 11개의 설명변수
| 변수 | 정의 | 값 |
| Survived | Survival |
0 = No, 1 = Yes category |
| Pclass | Ticket class |
1 = 1st, 2 = 2nd, 3 = 3rd category, ordinal |
| Sex | Sex | category |
| Age | Age in years | numeric |
| SibSp | # of siblings / spouses aboard the Titanic | numeric |
| Parch | # of parents / children aboard the Titanic | numeric |
| Ticket | Ticket number | numeric, char |
| Fare | Passenger fare | numeric |
| Cabin | Cabin number | char |
| Embarked | Port of Embarkation |
C = Cherbourg, Q = Queenstown, S = Southampton category |
데이터의 구조는 아래와 같습니다.
|
PassengerId |
Survived |
Pclass |
Name |
Sex |
Age |
SibSp |
Parch |
Ticket |
Fare |
Cabin |
Embarked |
|
1 |
0 |
3 |
Braund, Mr. Owen Harris |
male |
22 |
1 |
0 |
A/5 21171 |
7.25 |
NA |
S |
|
2 |
1 |
1 |
Cumings, Mrs. John Bradley (Florence Briggs Thayer) |
female |
38 |
1 |
0 |
PC 17599 |
71.2833 |
C85 |
C |
|
3 |
1 |
3 |
Heikkinen, Miss. Laina |
female |
26 |
0 |
0 |
STON/O2. 3101282 |
7.925 |
NA |
S |
|
4 |
1 |
1 |
Futrelle, Mrs. Jacques Heath (Lily May Peel) |
female |
35 |
1 |
0 |
113803 |
53.1 |
C123 |
S |
|
5 |
0 |
3 |
Allen, Mr. William Henry |
male |
35 |
0 |
0 |
373450 |
8.05 |
NA |
S |
각 변수들을 살펴보기 위해 info함수를 이용하면 아래와 같습니다.
df_train.info()
Age와 Cabin, Embarked의 경우, NA값이 존재하므로 결측치를 처리해야 합니다.
2. data preprocessing
2.1. data 결합
df_test['Survived']=999 #df_test의 target 변수에 '999' 넣기
df=pd.concat([df_train, df_test],axis=0,ignore_index=True)df_test 데이터에 target변수를 만들고, df_train과 df_test변수를 결합하였습니다.
2.2. NA값 살펴보기
msno.matrix(df, figsize=(12,5))
#AGE, CABIN NA값 많음
for col in df.columns:
na = 'column: {:>10}\t Percent of NaN value: {:.2f}%'.format(col, 100 * (df[col].isnull().sum() / df[col].shape[0]))
print(na)
# age와 embarked 채워넣기, cabin 변수 제거
msno 패키지를 이용하여 NA값을 살펴보면 위와 같습니다.
AGE 변수와 Embarked 변수의 경우, NA값을 채워넣고, Cabin변수는 변수의 70%이상이 비어있으므로 제거합니다.
2.3. EDA
2.3.1. TARGET변수(Survived)
pie=df_train['Survived'].value_counts().plot.pie(autopct='%.1f%%',cmap='Set3', startangle=90,table=True)
pie.set_title('Pie plot - Survived')
pie.set_label
pie.set_ylabel('')
plt.show()
# 죽은 사람의 비율이 더 높음
사망자가 61.6%로 더 많은 비율을 차지하고 있습니다.
2.3.2. Pclass(ordinal, categorical variable)
## 탑승자 분포
f, ax = plt.subplots(1,2,figsize=(18,8))
bar1=df_train[['Pclass','Survived']].groupby(['Pclass']).count().plot.bar(ax=ax[0])
bar1.set_title('Pclass - Occupant')
# pclass별 생존자
bar2=sns.countplot(hue='Survived',x='Pclass',data=df_train)
bar2.set_title('Pclass - Survived')
plt.show()
# class 3 이 가장 많고 생존자는 class 1이 가장 많다.
Pclass는 class3이 가장 많이 탑승하였으나 생존자는 class1이 가장 많은 것을 확인할 수 있습니다.
# class별 생존률
bar3=df_train[['Pclass','Survived']].groupby(['Pclass']).mean().plot.bar()
bar3.set_title('Pclass - Survived')
plt.show()
#생존률은 class 1 > class 2 > class 3 순이다. 
class별 생존률을 확인해보면 class1이 가장 높은 생존률을 보이는 것을 알 수 있습니다.
2.3.3. Sex(categorical)
f, ax = plt.subplots(1,2,figsize=(18,8))
# 성별 탑승자
bar1=sns.countplot(x='Sex', data=df_train, ax=ax[0])
bar1.set_title('Sex-occupant')
# 성별 생존자
bar2=sns.countplot(hue='Survived',x='Sex',data=df_train)
bar2.set_title('Sex - Survived')
plt.show()
# 남자 탑승자가 더 많고 남자는 사망자가 여자는 생존자가 더 많다.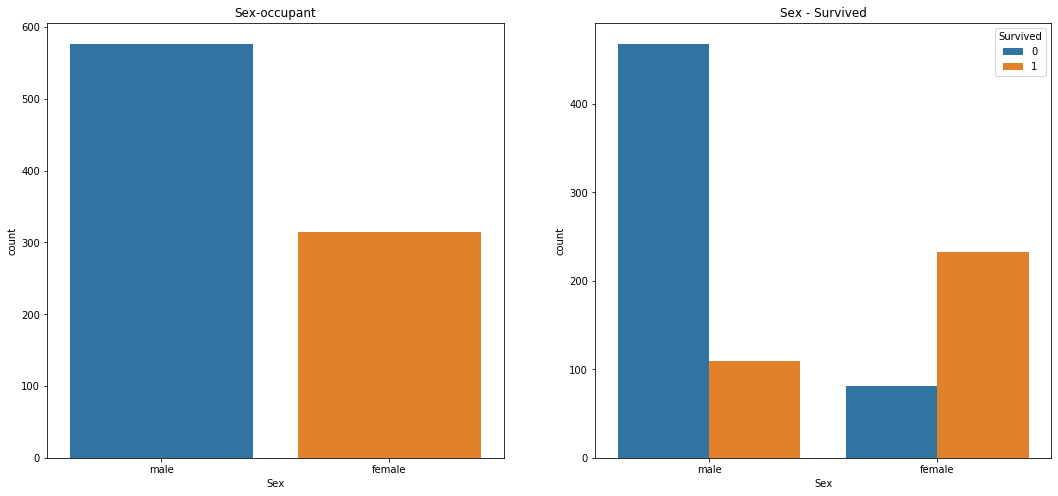
탑승자는 남성의 비율이 더 높으며 생존자 수는 여성이 더 많은 것을 알 수 있습니다.
# 성별 생존률
#성별 탑승자
df_train[['Sex','Survived']].groupby(['Sex']).mean().plot.bar()
plt.show()
# 여성 생존률이 3배 이상이다.
여성의 생존률이 더 높은 것을 알 수 있습니다. 구조 당시, 여성을 먼저 구조한 것이라 예상할 수 있습니다.
2.3.4. Name
이름 변수의 경우, 너무 많은 category를 가지므로 mr, mrs와 같은 호칭만 추출하였습니다.
# 이름에서 호칭만 추출
df['title']=""
for i in range(len(df['Name'])):
df['title'][i]=df['Name'][i].split(',')[1].split('.')[0].lower()
# 호칭에 따른 countplot
sns.countplot(y='title',data=df)
MR 호칭이 가장 많고, 4개의 호칭이 가장 많습니다.(mr, mrs, miss, master)
추후 분석에서 저 4개의 카테고리만 가지고 예측을 하면 좋을 것 같습니다.
2.3.5. Age
df['Age'].describe()
sns.distplot(df[df['Age']>0]['Age'])
plt.show()
#20~40부근이 가장 많다.
나이는 20대~30대가 주를 이루는 것을 알 수 있습니다.
2.3.6. Sibsp
sns.countplot(y='SibSp', data=df)
plt.show()
#형제가 없는 경우가 가장 많다.
형제가 없는 경우가 가장 많습니다.
2.3.7. Parch
sns.countplot(y='Parch', data=df)
plt.show()
#혼자인 경우가 가장 많다.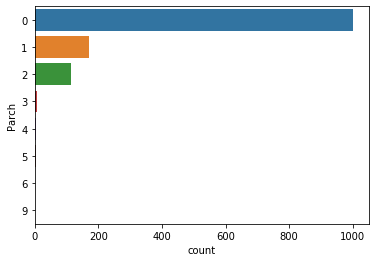
혼자 탑승한 경우가 가장 많습니다.
2.3.8. Ticket
df['Ticket'].value_counts()

동일한 티켓을 소지한 사람이 있는 것을 확인할 수 있습니다.
ticket의 개수가 1, 2, 3개 이상인 사람을 각각 Single, Double, Multiple으로 변환하였습니다.
df['Ticket_type']=""
for i in range(len(df['Ticket'])):
if df['Ticket'][i] in (df['Ticket'].value_counts()[df['Ticket'].value_counts()==1]).index:
df['Ticket_type'][i]="Single"
elif df['Ticket'][i] in (df['Ticket'].value_counts()[df['Ticket'].value_counts()==2]).index:
df['Ticket_type'][i]="Double"
else:
df['Ticket_type'][i]="Multiple"
df['Ticket_type']
sns.countplot(y='Ticket_type',data=df)
plt.show()
Single 티켓을 소지한 사람이 가장 많은 것을 확인할 수 있습니다.
2.3.9. Fare
df['Fare'].describe()
plt.figure(figsize=(12, 7))
sns.boxplot(x='Pclass',y='Fare',data=df_train)
#class1이 가장 비싼티켓
pclass가 가장 비싼 티켓임을 알 수 있습니다.
즉, class 1, class 2, class3 순으로 티켓이 비싸며 class 1 의 경우, 상류층이 많은 것이라 예상할 수 있습니다.
sns.distplot(df[df['Fare']>0]['Fare'])
plt.show()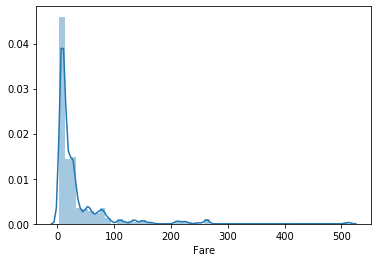
2.3.10. Embarked
bar=sns.countplot('Embarked', data = df)
bar.set_title('Count plot - Embarked')
plt.show()
Embarked 변수의 경우 'S'인 경우가 가장 많은 것을 알 수 있습니다.
2.4. NA값 처리하기
df.info()
2.4.1. Embarked 변수 채워넣기
Embarked 변수의 경우, 앞서 막대그래프를 통해서 S가 가장 많은 것을 확인하였습니다.
그러므로 S로 NA값을 채워넣었습니다.
#NaN values are replaced with 'S'
df['Embarked'].replace({np.nan:'S'} , inplace = True)2.4.2. 더미변수 처리하기
나머지 변수들의 NA값을 처리하기 이전에 category 변수들을 더미변수를 이용해 처리하였습니다.
#종속변수 : survived
# 설명변수 : pclass(category, ordinal), name(char), sex(category), age, sibsp, parch, ticket(char/num), fare, cabin(char), embarked(category)
df=pd.get_dummies(df,columns=['Pclass','Sex','title','Embarked','Ticket_type'])
2.4.3. NA값 채워넣기
# 문자 변수 제거(NAME은 추후에 어떻게 사용할지 생각해보기)
df.drop(columns = ['Cabin'] , inplace = True)
df.drop(columns=['Name'] , inplace = True)
df.drop(columns=['Ticket'] , inplace = True)
Cabin, Name, Ticket 변수를 제거하였습니다.
필요없는 변수를 제거한 후, Mice방법과 KNN방법을 이용하여 결측치를 채워넣었습니다.
# MICE 방법
from fancyimpute import IterativeImputer
MICE_imputer = IterativeImputer()
df_mice = df.copy()
df_mice.iloc[:,:] = MICE_imputer.fit_transform(df_mice) # 결과값을 데이터 프레임에 넣어주기
#Imputing using KNN :
from fancyimpute import KNN
knn_imputer = KNN()
df_knn = df.copy()
df_knn.iloc[:,:] = knn_imputer.fit_transform(df_knn)
# 결측치 처리 결과 그림으로 확인하기
sns.kdeplot(df['Age'] , c = 'r' , label = 'No imputation')
sns.kdeplot(df_knn['Age'] , c = 'g' , label = 'KNN imputation')
sns.kdeplot(df_mice['Age'] , c = 'b' , label = 'MICE imputation')
sns.kdeplot(df['Age'].fillna(df['Age'].mean()) , c = 'k' , label = 'Fillna_Mean')
plt.show()
결측치를 처리한 후, 그래프로 확인해보면 위와 같습니다.
2.5. data 다시 나누기
#Spiltting Test and Train Datas:
dfm_train = df_mice[df_mice['Survived'] != 999]
dfm_test = df_mice[df_mice['Survived'] == 999]
#test set의 target변수 제거
dfm_test.drop(columns = 'Survived', inplace = True)데이터 전처리를 끝낸 후, 다시 train데이터와 test데이터로 split 하였습니다.
'데이터 분석' 카테고리의 다른 글
| [서평] 이기적 빅데이터 분석기사 실기 교재 (0) | 2022.11.14 |
|---|---|
| [서평] 가장 빨리 만나는 스벨트 (0) | 2022.04.10 |
| [서평] 2022 공개적 빅데이터분석기사 실기 교재 추천 (0) | 2022.02.21 |
| kaggle) Titanic data 분석하기 2. 모델링(xgboost, RandomForest) (0) | 2020.04.26 |



